

Numerical Linear Algebra Software
(based on slides written by Michael Grant)
• BLAS, ATLAS
• LAPACK
• sparse matrices
most memory usage and computation time in optimization methods is spent on numerical linear algebra, e.g.,
• constructing sets of linear equations (e.g., Newton or KKT systems)
– matrix-matrix products, matrix-vector products, . . .
• and solving them
– factoring, forward and backward substitution, . . .
. . . so knowing about numerical linear algebra is a good thing
• Matlab (Octave, . . . ) is OK for prototyping an algorithm
• but you’ll need to use a real language (e.g., C, C++, Python) when
– your problem is very large, or has special structure
– speed is critical (e.g., real-time)
– your algorithm is embedded in a larger system or tool
– you want to avoid proprietary software
• in any case, the numerical linear algebra in Matlab is done using
standard free libraries
How to write numerical linear algebra software
DON’T!
written by people who had the foresight to understand the future benefits
of a standard suite of “kernel” routines for linear algebra.
created and organized in three levels:
• Level 1, 1973-1977: O(n) vector operations: addition, scaling, dot
products, norms
• Level 2, 1984-1986: O(n^2) matrix-vector operations: matrix-vector
products, triangular matrix-vector solves, rank-1 and symmetric rank-2
updates
• Level 3, 1987-1990: O(n^3) matrix-matrix operations: matrix-matrix
products, triangular matrix solves, low-rank updates
| Level 1 | addition/scaling dot products, norms |
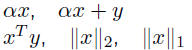 |
| Level 2 | matrix/vector products rank 1 updates rank 2 updates triangular solves |
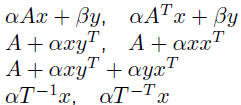 |
| Level 3 | matrix/matrix products
rank-k updates |
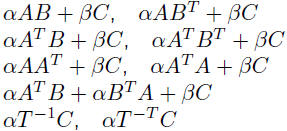 |
BLAS routines have a Fortran-inspired naming convention:
| cblas_ | X | XXXX |
| prefix | data type | operation |
data types:
| s single precision real | d double precision real |
| c single precision complex | z double precision complex |
operations:
axpy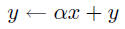 |
dot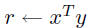 |
nrm2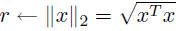 |
asum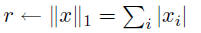 |
example:
| cblas_ddot | double precision real dot product |
BLAS naming convention: Level 2/3
| cblas_ | X | XX | XXX |
| prefix | data type | structure | operation |
matrix structure:
| tr triangular | tp packed triangular | tb banded triangular |
| sy symmetric | sp packed symmetric | sb banded symmetric |
| hy Hermitian | hp packed Hermitian | hn banded Hermitian |
| ge general | gb banded general |
operations:
mv 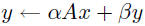 |
sv 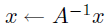 (triangular only) (triangular only) |
r 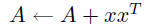 |
r2 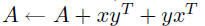 |
mm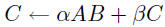 |
r2k 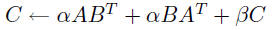 |
examples:
| cblas_dtrmv | double precision real triangular matrix-vector product |
| cblas_dsyr2k | double precision real symmetric rank-2k update |
Using BLAS efficiently
always choose a higher-level BLAS routine over multiple calls to a lower-level BLAS routine
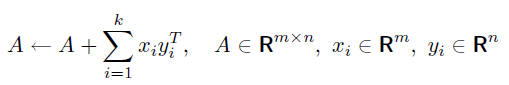
two choices: k separate calls to the Level 2 routine cblas_dger
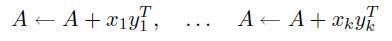
or a single call to the Level 3 routine cblas_dgemm
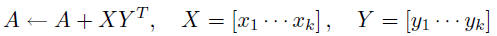
the Level 3 choice will perform much better
Is BLAS necessary?
why use BLAS when writing your own routines is so easy?
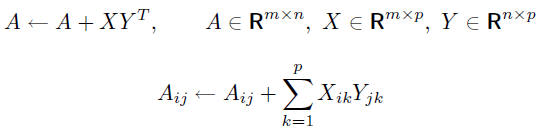
void matmultadd( int m, int n, int p, double* A,
const double* X, const double* Y ) {
int i, j, k;
for ( i = 0 ; i < m ; ++i )
for ( j = 0 ; j < n ; ++j )
for ( k = 0 ; k < p ; ++k )
A[ i + j * n ] += X[ i + k * p ] * Y[ j + k * p ];
}
• tuned/optimized BLAS will run faster than your home-brew version —
often 10× or more
• BLAS is tuned by selecting block sizes that fit well with your processor,
cache sizes
• ATLAS (automatically tuned linear algebra software)
uses automated code generation and testing methods to generate an
optimized BLAS library for a specific computer
Improving performance through blocking
blocking is used to improve the performance of matrix/vector and
matrix/matrix multiplications, Cholesky factorizations, etc.
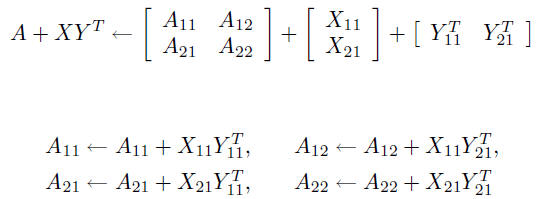
optimal block size, and order of computations, depends on details of
processor architecture, cache, memory
Linear Algebra PACKage (LAPACK)
LAPACK contains subroutines for solving linear systems and performing
common matrix decompositions and factorizations
• first release: February 1992; latest version (3.0): May 2000
• supercedes predecessors EISPACK and LINPACK
• supports same data types (single/double precision, real/complex) and
matrix structure types (symmetric, banded, . . . ) as BLAS
• uses BLAS for internal computations
• routines divided into three categories: auxiliary routines,
computational routines, and driver routines
LAPACK computational routines
computational routines perform single, specific tasks
• factorizations: LU, LLT /LLH, LDLT /LDLH, QR, LQ, QRZ,
generalized QR and RQ
• symmetric/Hermitian and nonsymmetric eigenvalue decompositions
• singular value decompositions
• generalized eigenvalue and singular value decompositions
LAPACK driver routines
driver routines call a sequence of computational routines to solve standard
linear algebra problems, such as
• linear equations: AX = B
• linear least squares: minimizex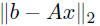
• linear least-norm:
| minimizey |
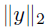 |
| subject to | d = By |
• generalized linear least squares problems:
| minimizex |
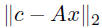 |
minimizey |
|
| subject to | Bx = d | subject to | d = Ax + By |
LAPACK example
solve KKT system
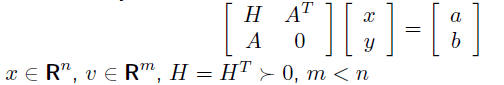
option 1: driver routine dsysv uses computational routine dsytrf to
compute permuted LDLT factorization
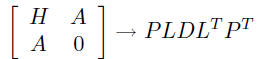
and performs remaining computations to compute solution
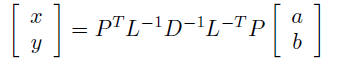
option 2: block elimination
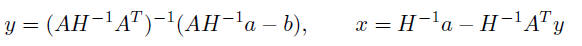
first we solve the system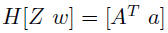 using
driver routine dspsv
using
driver routine dspsv
• then we construct and solve (AZ)y = Aw − b using dspsv again
• x = w − Zy
using this approach we could exploit structure in H, e.g., banded
What about other languages?
BLAS and LAPACK routines can be called from C, C++, Java, Python, . . .
an alternative is to use a “native” library, such as
• C++: Boost uBlas, Matrix Template Library
• Python: NumPy/SciPy, CVXOPT
• Java: JAMA
Sparse matrices
• A ∈ Rm×n is sparse if it has “enough zeros that it pays to take
advantage of them” (J. Wilkinson)
• usually this means nnz, number of elements known to be nonzero, is
small: nnz
 mn
mn
sparse matrices can save memory and time
• storing A ∈ Rm×n using double precision
numbers
– dense: 8mn bytes
– sparse: ≈ 16nnz bytes or less, depending on storage format
• operation y ← y + Ax:
– dense: mn flops
– sparse: nnz flops
• operation x ← T-1x, T ∈ Rn×n triangular, nonsingular:
– dense: n^2/2 flops
– sparse: nnz flops
Representing sparse matrices
• several methods used
• simplest (but typically not used) is to store the data as list of (i, j,Aij)
triples
• column compressed format: an array of pairs (Aij, i), and an array of
pointers into this array that indicate the start of a new column
• for high end work, exotic data structures are used
• sadly, no universal standard (yet)
Sparse BLAS?
sadly there is not (yet) a standard sparse matrix BLAS library
• the “official” sparse BLAS
• C++: Boost uBlas, Matrix Template Library, SparseLib++
• Python: SciPy, PySparse, CVXOPT
Sparse factorizations
libraries for factoring/solving systems with sparse matrices
• most comprehensive: SuiteSparse (Tim Davis)
• others include SuperLU, TAUCS, SPOOLES
• typically include
typically include
– A = PLLTPT Cholesky
– A = PLDLTPT for symmetric indefinite systems
– A = P1LUPT2 for general (nonsymmetric) matrices
P, P1, P2 are permutations or orderings
Sparse orderings
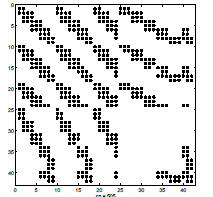
sparse orderings can have a dramatic effect on the sparsity of a factorization
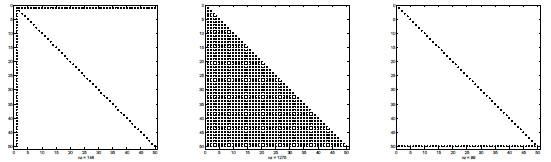
• left: spy diagram of original NW arrow matrix
• center: spy diagram of Cholesky factor with no permutation (P = I)
• right: spy diagram of Cholesky factor with the best permutation (permute 1 →
n)
Sparse orderings
• general problem of choosing the ordering
that produces the sparsest factorization is hard
• but, several simple heuristics are very effective
• more exotic ordering methods, e.g., nested disection, can work very well
Symbolic factorization
• for Cholesky factorization, the ordering can be chosen
based only on the
sparsity pattern of A, and not its numerical values
• factorization can be divided into two stages: symbolic
factorization and
numerical factorization
– when solving multiple linear systems with identical
sparsity patterns,
symbolic factorization can be computed just once
– more effort can go into selecting an ordering, since it will be
amortized across multiple numerical factorizations
• ordering for LDLT factorization usually has
to be done on the fly, i.e.,
based on the data
Other methods
we list some other areas in numerical linear algebra that
have received
significant attention:
• iterative methods for sparse and structured linear
systems
• parallel and distributed methods (MPI)
• fast linear operators: fast Fourier transforms (FFTs), convolutions,
state-space linear system simulations
there is considerable existing research, and accompanying
public domain
(or freely licensed) code